

今日:0
文章:78

今日:0
文章:13

今日:0
文章:9

今日:0
文章:137

今日:0
文章:30

今日:0
文章:63
今日:0
文章:19

3028

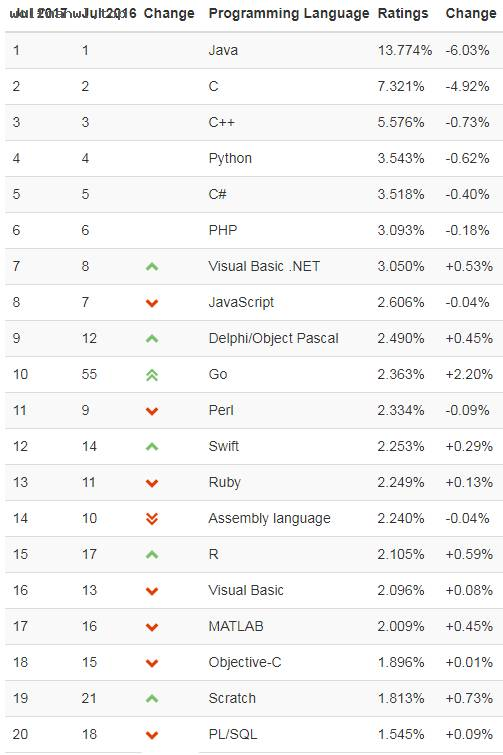
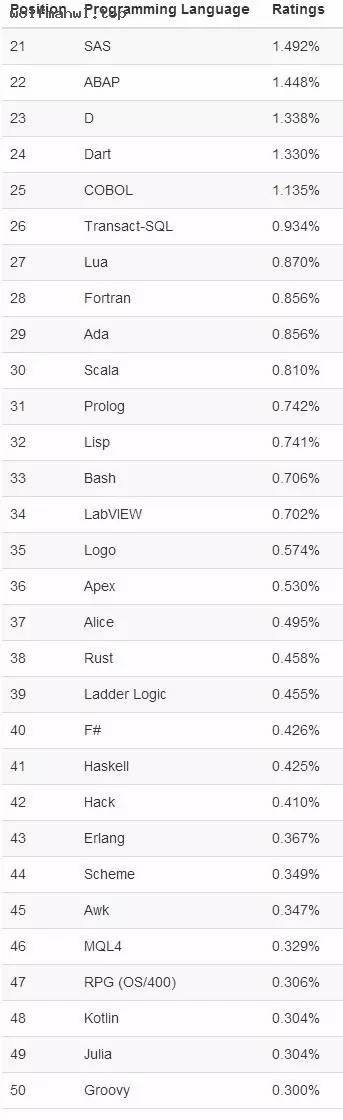
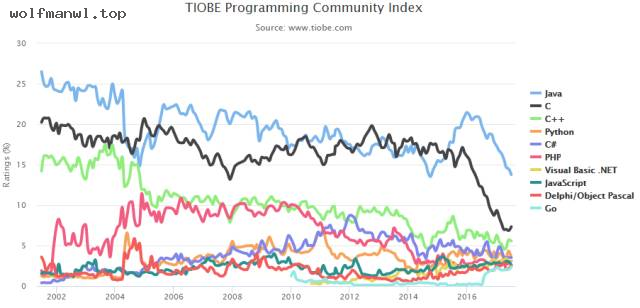
TIOBE编程语言社区发布了2017年7月排行榜,这次排行和6月相比变动不大,Java、C、C++和Python仍然稳定保持在前4甲。Go 语言今年一路飙升,本月终于进入前10名,2016年同期可是才55名,这个速度果然是够猛,究其原因或许跟大数据人工智能发展趋势有关。上个月谷歌宣布了安卓开发全面支持Kotlin,Kotlin上个月也首次进入前50名。 本月Kotlin未能继续发挥热度,下跌 4 位(44名降到48名)。从目前趋势上看,Go 语言一直保持上升势头的话,将同 JavaScript 、 Python 等“明星”语言并驾齐驱,成为最值得学习的编程语言之一。2017年7月编程语言排行榜 Top 20 榜单: 第20-50榜单:Top 10 编程语言 TIOBE 指数走势(2002-2016) 【说明】TIOBE 编程语言社区排行榜是编程语言流行趋势的一个指标,每月更新,这份排行榜排名基于互联网上有经验的程序员、课程和第三方厂商的数量。排名使用著名的搜索引擎(诸如 Google、MSN、Yahoo!、Wikipedia、YouTube 以及 Baidu 等)进行计算。请注意这个排行榜只是反映某个编程语言的热门程度,并不能说明一门编程语言好不好,或者一门语言所编写的代码数量多少。
2881
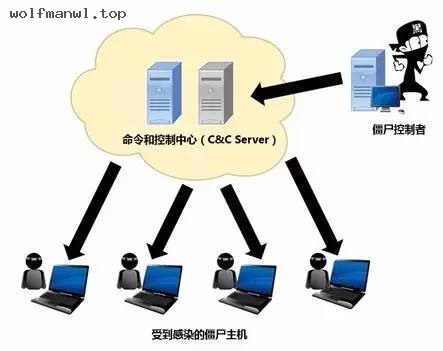
6月27日,一种新型勒索病毒NotPetya席卷全球,其中包括切尔诺贝利核电站、印度最大的集装箱货港和一些美国医院。就像5月的WannaCry一样,这个恶意软件会对电脑里所有的数据进行加密,并向用户索取比特币作为解密的条件。虽然这种会封锁电脑中所有文件的病毒正有愈演愈烈的趋势,但这还不是最坏的。据安在(ID:AnZer_SH)了解到,与WannaCry一样,NotPetya 也是利用了美国国家安全局(NSA)被盗的网络武器库中泄露的Windows系统漏洞 ——“永恒之 蓝”(EternalBlue)。而与WannaCry不同的是,它并没有任何安全开关的设计。NotPetya 先会通过被破解的软件更新来寻找寄主,并从电脑内存中获取管理权限进行扩散。通过 这种手段,它可以迅速的在一个组织的内部网络中扩散。目前为止,我们还不清楚这次网络袭击的幕后黑手是谁。但是由于乌克兰的各大公共和商业系统遭到了严重的攻击(其实乌克兰在上个月遭受了三起大型勒索病毒的袭击),有人推断俄罗斯可能介入了这次的事件。不管怎么说,花点时间来研究一下这个问题是有意义的。勒索病毒的入侵都会给被攻击机构造成一定的影响:若影响不大,IT部门则需要浪费时间和资源在恢复备用数据上;但若影响严重,这些病毒就会摧毁数据或强迫受害者支付大量的赎金。更让人难以接受的是,如果这种病毒攻击的目标是医院这种机构,这可能就是人命关天的大事了。目前,这轮勒索病毒都是利用了Windows XP的弱点。微软已不再支持该系统,而它最近的更新,即ServicePack 3(第三服务包),也已经差不多有10年了(不过,由于最近对其漏洞的攻击,微软罕见的对其漏洞发布了补丁包)。据安在(ID:AnZer_SH)了解,目前,很多机构依然依赖着这个古老并有大量隐患的操 作系统。不过,只要有足够的资源来进行升级换代,这并不是个大问题。而对于我们现在所面对的最大安全威胁---僵尸网络来说,就没这么简单了。这些由互联网连接起来的设备——如网络摄像头或数字视频录像机,正逐渐成为恶意攻击者的利用目标。其中,它们最常见的用处就是实施分布式拒绝服务(DDoS)攻击,即向目标服务器发动密集式的数据请求,使之无法提供服务。近期,这种攻击影响最大的例子就是去年被Mirai僵尸网络击溃的Dyn了。Dyn是一个庞大的域名系统(DNS),负责为试图连接网站的用户提供正确的地址。而这场袭击导致了美国东海岸地区大范围的断网。僵尸网络也被《麻省理工科技评论》评为2017年的10大突破技术之一。该文章的作者,安全专家Bruce Schneier表示,在未来几年内,僵尸病毒会变得越来越强,因为这些易受攻击的设备数量会以指数级增长。如果这种攻击以更重要、更核心的网络服务为目标的话,它们所造成的后果也会越来越严重:理论上来讲,更大的网络系统、更多的网站可能会因此被迫下线。更重要的问题在于,一个系统被击破的原因不一定是因为该机构没有及时更新系统,而是被大量廉价的家庭和商用的设备联合起来猛攻。甚至那些专门用来抵抗分布式拒绝服务攻击的安全产品也不完全能抵挡大规模的攻击。安全专家已经警告美国国会,这是一个很现实的问题,并很有可能只能通过对物联网设备的法规来解决。特朗普政府也已承诺要击垮僵尸网络。然而我们距离找出真正有效的解决方案还有很长的路要走。僵尸网络依旧是一个极难抵抗的安全隐患,虽然目前占据头条的是勒索病毒。有一天,当僵尸网络进入你的视线时,或许我们已付出了极大的代价。



2922
做外贸的网站一般都不想让国内人访问,可以采用如下的方法:1. 从APNIC获取一份国家与地区IP段数据 ftp://ftp.apnic.net/apnic/dbase/data/country-ipv4.lst2. 将中国的数据整理取出(用excel的数据筛选功能)3. 编写PHP代码如下:<?php
function ipCIDRCheck ($IP, $CIDR) {
list ($net, $mask) = split (“/”, $CIDR);
if($mask>16){
$net=$net.”.0″;
}else{
$net=$net.”.0.0″;
}
$ip_net = ip2long ($net);
$ip_mask = ~((1 << (32 – $mask)) – 1);
$ip_ip = ip2long ($IP);
$ip_ip_net = $ip_ip & $ip_mask;
return ($ip_ip_net == $ip_net);
}
$subnets=<<<Eof
60.0/11
60.55/16
60.63/16
60.160/11
60.194/15
60.200/13
60.208/12
60.232/15
60.235/16
60.245.128/17
60.247/16
60.252/16
60.253.128/17
60.255/16
Eof;
$subnetarray=explode(“\n”,$subnets);
foreach($subnetarray as $subnet){
if(ipCIDRCheck (“60.168.86.219″, $subnet)){
echo “60.168.86.219 in => “.$subnet;
//取得用户ip后,与之比较,如果匹配,就可以在这里显示一个错误页,或重定向了
};
}
?>程序执行时间平均20毫秒,篇幅有限,仅列出部分IP段,完整的请自行获取。

2996
 甜言蜜语背后的危险
甜言蜜语背后的危险
甜言蜜语背后的危险 ——社工工程学你们好我是c3 我不是什么社工帝 小白一个 !根据自己所掌握的知识写个教程!让大家了解什么是‘社工’!社工思路一、什么是社会工程学呢?我在这里援引Ian Mann在2008年所著的Hacking the Human一书 这本书对社工给出的定义是:通过操纵人来实施某些行为或泄露机密信息的一种攻击艺术!说白了就是对人的欺骗!但是要欺骗的天衣无缝、神不知鬼不觉的完成你的这个行动!还是需要很多技巧和策略.而这种欺骗无法像其他的技术那么的循规蹈矩。同时有些时候只可意会而不可言传,因此它就被称为一种‘艺术’!其实社工在中国的历史上有很多实例!比如著名的《三十六计》和《三国演义》尤其是三国演义中第四十五回《群英会蒋干中计》,讲的是周瑜使用借刀杀人反间计,利用曹操的谋士蒋干来江东说祥自己的机会,诱骗蒋干盗书,离间蔡瑁张允与曹操的关系,借曹操之手除掉蔡张二人,里面周瑜设计、用计以及曹操中计过程的描述,完美的体现了社会工程学的思想。社工的原理就是通过分析攻击对象的心理弱点、利用人类的本能反应以及好奇、贪婪这些类似的心理特征!使用假冒,欺骗,引诱等手段开达成攻击目标的一种攻击手段。社工其实蕴含了各式各样的灵活构思和变化因素。无论何时何地在套取所需要的信息和操纵对方之前,攻击的实施者都必须掌握大量的相关知识基础。花费时间去从事资料的收集和整理,还要去进行必要的沟通工作!二、社会工程学技术框架其实社工基本上可以分为四个环节!1,信息收集2,诱导3,托辞4,心理影响 1信息收集可以分为:收集渠道 信息源 诱导:诱导目标 场景铺垫 如何去诱导成功托辞:托辞的设计原则 规划 如何成功心理影响:主要是心理战术的灵活利用信息收集的渠道很多例如:搜索引擎,whios查询,社交媒体,如何去判断你收集的资料是不是对的呢?例如你要去社工一个人小n 你从其他渠道获取到了他的资料 这个时候有多种方法去证实,沟通,从他的空间里找漏洞 例如空间访客 你试着去点访客资料查看 看看那个地方的人占多数。频率多高!这样来基本的判断 当然你也可以去找他朋友,这样的思路很多就是看你如何去利用,信息收集主要是能准确的抓住重点 细节!2,诱导:意思就是说一些表面普通而且无关的话,从对方回答中提取有用的信息。怎样去提高诱导能力:1:在目标进行社工时表现要很自然2:学习相关知识3,不能够贪心:怎样说呢。假如你已经从目标那里套到了一些资料 不能贪婪的想要套取更多,这样会引起目标的警觉性!诱导技巧:迎合目标的自我感觉 表达自己和她(他)有共同兴趣 托辞:这个技巧是对现实社工来用的主要 说白了就是多方位的套路 有些时候你知道了对方的大概位置 可以从交谈中慢慢的说出自己是哪里的(和目标一样的地址)这样的话有些人觉得是个老乡 那么他对你的警觉性必然会少点!这里我着重说一下这个心理影响、基本原则:设置明确的目标、与目标建立关系、不能够循规蹈矩。心理影响的一些战术:我这里说网络上的,利用承诺与一致性,从众心理,好奇心 贪婪 自大自信、谦虚.思路其实很多,就好比有一次我们几个朋友一起去社工一个小学生!那个人是什么黑客送软件 我们因为比的是社群!我就去问她现在是不是有几个人问你拜师不 要没要你的微信 支付宝 他就说是的 然后当时我知道了他是xx地方的!我就说那几个人不是真心拜师。而是去套路你的!别信!这个时候我就用扣扣位置定位拉取到那个地方,就说什么我看你和我是老乡我真的看不下去了!说了半天废话!我就说要管理!这人很倔 就是不给但是经过我这么一搞他就说兄弟帮我多啦点人!后面的就不用说了!社工小学生最常用的莫过于利用贪婪这一点!其实说句实话社工真心不难!社工思路不能够去定位这得根据你的目标!你自己去想该如何怎么套取!有人曾经给我说过社工并不是社资料 最高的而是拿到他手里的权限!在学习社工之前你得自己先认知自我!社工再多的教程都比不了自己的实战经验!社工查询的网站和最基础的思路我想的话是个人都知道的!这些就没必要说出来了!基本的社工思路1.百度google搜索QQ号信息,QQ邮箱信息2.百度贴吧关键字搜索QQ号信息,QQ邮箱信息2.1 如果搜索到,拿到贴吧帐号,请继续用贴吧帐号按照1,2步搜索,以此类推3.社工库查询QQ号的信息,可通过QQ群数据库,查备注名,查他拥有的QQ群,这个一般比较准群,可以查到真实姓名,或者拥有哪些群(比如查到XX中学20**届多少班),然后再网上查该学校的20**届毕业名单4.如果只有真实姓名,用真实姓名去查询人人,腾讯朋友等,你会获得一些更多的信息(重名的很多,但你查出学校,就知道大概年龄和大致家庭地址)不出意外,你可以获得以下信息中的N种可能性QQ号真实姓名贴吧帐号人人帐号-真实照片腾讯朋友-真实照片手机号 微信号 手机微店 以上信息,又可进一步社工百度手机号,除了能获取归属地之外,还可能获取到一些他在网上留下的信息百度,google他在网上的网名(贴吧名)百度,google搜图,搜他的真实照片百度,google真实姓名通过贴吧,人人,找他的动态,进一步发现其他资料反正思路就是这样,通过一个信息,去进一步获取他在网上的其他信息,用每个信息都去重复之前的步骤,这就是最简单的社工。本人c3 qq1586489579. 大佬勿喷!
5674
打开这些网页之后,随便在键盘上打字就会在屏幕上出现各种代码了,记得按下 F11 (Windows) 或 ⌘-Shift-F(Mac) 将浏览器全屏显示,这样装 X 效果更好!另外,按下数字小键盘的 / * - + 2 8 0 等按键可以弹出不同的特效,譬如出现登录成功、登录失败、雷达扫描、导弹发射等等效果,按下 ESC 可以移除它们。注意,推荐使用 Chrome、FireFox、IE11 等比较先进的浏览器进行访问,如果还在使用 IE6 之类的老旧浏览器可能效果会不正常。http://hackcode.ishoulu.com/scp/http://hackcode.ishoulu.com/combine/http://hackcode.ishoulu.com/blackmesa/http://hackcode.ishoulu.com/blackmesa/http://hackcode.ishoulu.com/matrix/http://hackcode.ishoulu.com/swan/http://hackcode.ishoulu.com/64/
3103
如果你初来乍到,大数据看起来很吓人!根据你掌握的基本理论,让我们专注于一些关键术语以此给你的约会对象、老板、家人或者任何一个人带来深刻的印象。让我们开始吧:1.算法。“算法”如何与大数据相关?即使算法是一个通用术语,但大数据分析使其在当代更受青睐和流行。2.分析。年末你可能会收到一份来自信用卡公司寄来的包含了全年所有交易记录的年终报表。如果你有兴趣进一步分析自己在食物、衣服、娱乐等方面具体花费占比呢?那你便是在做“分析”了。你正从一堆原始数据中来吸取经验,以帮助自己为来年的消费做出决策。如果你正在针对整个城市人群对Twitter或Facebook的帖子做同样的练习呢?那我们便是在讨论大数据分析了。大数据分析的实质是利用大量数据来进行推断和讲故事。大数据分析有3种不同到的类型,接下来便继续本话题进行依次讨论。3.描述性分析。刚刚如果你告诉我,去年你的信用卡消费在食物上花费了25%、在服装上花费了35%、娱乐活动上花费了20%、剩下的就是杂七杂八的事项,这种便是描述性分析。当然你还可以参考更多的细节。4.预测分析。如果你根据过去5年的信用卡历史记录来进行分析,并且划分具有一定的连续性,则你可以高概率预测明年将与过去几年相差无几。此处需要注意的细节是,这并不是“预测未来”,而是未来可能会发生的“概率”。在大数据预测分析中,数据科学家可能会使用类似机器学习、高级的统计过程(后文将对这些术语进行介绍)等先进的技术去预测天气、经济变化等。5.规范分析。沿用信用卡交易的案例,你可能想要找出哪方面的支出(级食品、服装、娱乐等)对自己的整体支出产生巨大的影响。规范分析建立在预测分析的基础之上,包含了“行动”记录(例如减少食品、服装、娱乐支出),并分析所得结果来“规定”最佳类别以减少总体支出。你可以尝试将其发散到大数据,并设想高管们如何通过查看各种行动的影响来做出数据驱动的决策。6.批处理。虽然批量数据处理在大型机时代就早已出现,但大数据交给它更多大数据集处理,因此赋予了批处理更多的意义。对于一段时间内收集到的一组事务,批量数据处理为处理大量数据提供了一种有效的方法。后文将介绍的Hadoop便是专注于批量数据处理。7. Cassandra是由Apache Software Foundation管理的一款流行的开源数据库管理系统。很多大数据技术都归功于Apache,其中Cassandra的设计初衷便是处理跨分布式服务器的大量数据。8. 云计算。显而易见云计算已经变得无所不在,所以本文可能无须赘述,但为了文章的完整性还是佐以介绍。云计算的本质是在远程服务器上运行的软件和(/或)数据托管,并允许从互联网上的任何地方进行访问。9. 集群计算。它是一种利用多台服务器的汇集资源的“集群”来进行计算的奇特方式。在了解了更多技术之后,我们可能还会讨论节点、集群管理层、负载平衡和并行处理等。10. 黑暗数据。依我看来,这个词适用于那些吓得六神无主的高级管理层们。从根本上来说,黑暗数据是指那些被企业收集和处理但又不用于任何有意义用途的数据,因此描述它是“黑暗的”,它们可能永远被埋没。它们可能是社交网络信息流、呼叫中心日志、会议笔记,诸如此类。人们做出了诸多估计,在60-90%的所有企业数据都可能是“黑暗数据”,但无人真正知晓。11. 数据湖。当我第一次听到这个词的时候,我真的以为有人在开愚人节的玩笑。但它真的是个术语!数据湖是一个原始格式的企业级数据的大型存储库。虽然此处讨论的是数据湖,但有必要再一起讨论下数据仓库,因为数据湖和数据仓库在概念上是极其相似的,都是企业级数据的存储库,但在清理和与其他数据源集成之后的结构化格式上有所区别。数据仓库常用于常规数据(但不完全)。据说数据湖能够让用户轻松访问企业级数据,用户真正按需知道自己正在寻找的是什么、如何处理并让其智能化使用。12. 数据挖掘。数据挖掘是指利用复杂的模式识别技术从大量数据中找到有意义的模式、提取见解。这与我们前文讨论的使用个人数据做分析的术语“分析”密切相关。为了提取出有意义的模式,数据挖掘者使用统计学(是呀,好老的数学)、机器学习算法和人工智能。13.数据科学家。我们谈论的是一个如此热门的职业!数据科学家们可以通过提取原始数据(难道是从前文所说的数据湖中提取的?),处理数据,然后提出新见解。数据科学家所需具备的一些技能与超人无异:分析、统计、计算机科学、创造力、故事讲述和理解业务环境。难怪他们能获得如此高的薪水报酬。14.分布式文件系统。由于大数据太大而无法在单个系统上进行存储,分布式文件系统提供一种数据存储系统,方便跨多个存储设备进行大量数据的存放,并有助于降低大量数据存储的成本和复杂度。15. ETL。ETL分别是extract,transform,load的首字母缩写,代表提取、转化和加载的过程。 它具体是指“提取”原始数据,通过数据清洗/修饰的方式进行“转化”以获得 “适合使用”的数据,进而“加载”到合适的存储库中供系统使用的整个过程。尽管ETL这一概念源于数据仓库,但现在也适用于其它情景下的过程,例如在大数据系统中从外部数据源获取/吸收数据。16. Hadoop。人们一想起大数据就能立即想到Hadoop。 Hadoop(拥有可爱的大象LOGO)是一个开源软件框架,主要组成部分是Hadoop分布式文件系统(HDFS),Hadoop部署了分布式硬件以支持大型数据集的存储、检索和分析。如果你真的想给别人留下深刻的印象,还可以谈谈YARN(Yet Another Resource Schedule,另一个资源调度器),正如其名,它也是一个资源调度器。我由衷佩服这些为程序命名的人。为Hadoop命名的Apache基金会还想出了Pig,Hive和Spark(没错,它们都是各种软件的名称)。这些名字难道不让你感到印象深刻吗?17. 内存计算。一般来说,任何可以在不访问I / O的情况下进行的计算预计会比需要访问I/O的速度更快。内存内计算是一种能够将工作数据集完全转移到集群的集体内存中、并避免了将中间计算写入磁盘的技术。Apache Spark便是一种内存内计算系统,它与I / O相比,在像Hadoop MapReduce这样的系统上绑定具有巨大的优势。18. IOT。最新的流行语是物联网(Internet of things,简称IOT)。IOT是通过互联网将嵌入式对象(传感器、可穿戴设备、汽车、冰箱等)中的计算设备互连在一起,并且能够发送/接收数据。IOT产生了大量的数据,这为呈现大数据分析提供了更多的机会。19.机器学习。机器学习是为了设计一种基于提供的数据能够进行不断学习、调整、改进的系统的设计方法。机器使用预测和统计的算法进行学习并专注于实现“正确的”行为模式和简见解,随着越来越多的数据注入系统它还在不断进行优化改进。典型的应用有欺诈检测、在线个性化推荐等。20.MapReduce。MapReduce的概念可能会有点混乱,但让我试一试。MapReduce是一个编程模型,最好的理解方法是将Map和Reduce是看作两个独立的单元。在这种情况下,编程模型首先将大数据的数据集分成几个部分(技术术语上是称作“元组”,但本文并不想太过技术性),因此可以部署到不同位置的不同计算机上(即前文所述的集群计算),这些本质上是Map的组成部分。接下来该模型收集到所有结果并将“减少”到同一份报告中。 MapReduce的数据处理模型与hadoop的分布式文件系统相辅相成。21.NoSQL。乍一听这像是针对传统关系型数据库管理系统(RDBMS)的面向对象的SQL(Structured Query Language, 结构化查询语言)的抗议,其实NoSQL代表的是NOT ONLY SQL,意即“不仅仅是SQL”。 NoSQL实际上是指被用来处理大量非结构化、或技术上被称作“图表”(例如关系型数据库的表)等数据的数据库管理系统。NoSQL数据库一般非常适用于大型数据系统,这得益于它们的灵活性以及大型非结构化数据库所必备的分布式结构。22.R语言。有人能想到比这个编程语言更糟糕的名字吗?是的,’R’是一门在统计计算中表现非常优异的编程语言。如果你连’R’都不知道,那你就不是数据科学家。(如果你不知道’R’,就请不要把那些糟糕的代码发给我了)。这就是在数据科学中最受欢迎的语言之一的R语言。23. Spark(Apache Spark)。Apache Spark是一种快速的内存内数据处理引擎,它可以高效执行需要快速迭代访问数据集的流、机器学习或SQL工作负载。Spark通常比我们前文讨论的MapReduce快很多。24.流处理。流处理旨在通过“连续”查询对实时和流数据进行操作。结合流分析(即在流内同时进行连续计算数学或统计分析的能力),流处理解决方案可以被用来实时处理非常大的数据。25. 结构化和非结构化数据。这是大数据5V中的“Variety”多样性。结构化数据是能够放入关系型数据库的最基本的数据类型,通过表的组织方式可以联系到任何其他数据。非结构化数据则是所有不能直接存入关系数据库中的数据,例如电子邮件、社交媒体上的帖子、人类录音等。

2776
5G时代渐行渐近,在人们对丰富应用充满憧憬的同时,也更加关注5G技术的发展。5G对于网络架构将提出哪些新的需求?什么样的技术创新才符合5G演进方向?运营商将以怎样的姿态全面拥抱5G?在日前召开的“网络重构与5G技术研讨沙龙”上,来自业界各方的嘉宾对于这些业界关注的重点问题展开了思想碰撞,论道5G网络重构。5G,革命性变革开启“5G时代,网络架构将发生革命性变革。”中国信息通信研究院杨红梅抛出了这一观点。她认为,5G时代物联网和移动通信网业务将融合在一起,催生包括增强移动宽带(eMBB)、海量机器类通信(mMTC),以及超高可靠低时延通信(URLLC)在内的三大类典型应用。这三类业务的特点与传统电信业务有很大不同,因而5G必须在无线技术和核心网技术上进行变革与创新,引入大规模天线、超密集组网、新型多址、全频谱接入等技术。相比较2G、3G、4G网络,5G网络架构最大的变化就是更加扁平化。同时,5G还需要特别灵活的网络架构以实现资源的按需调配。杨红梅表示,5G的技术创新有两大方向:一是为了支撑严苛的通信指标,如体验速率、端到端时延等,在接入网层面需要灵活的网络构架支持多种接入技术;另一方面,5G还需要在无线资源智能化的控制、边缘计算、功能重构、控制转发/分离等方面展开创新。安全性是5G网络构架重构时需要重点考虑的问题。杨红梅认为,之前的网络建设经验证明,在网络设计之初就应该将安全问题考虑在其中,而对于5G网络而言,由于更多新业务和新终端形态的引入,安全性的意义更加凸显。5G催生的大量差异化的业务场景,SDN/NFV等技术的引入,商业模式上的创新,以及大量的物联网设备接入到运营商的网络中,都意味着5G将对安全提出更高的要求。具体而言,多种接入技术采用的安全机制各不相同,为了改善用户业务体验和提高鉴权认证效率,在5G网络构架设计时应考虑采用统一的认证构架。同时,由于大量的低成本的物联网设备接入网络,如何满足这些设备的安全和隐私保护需求,也是要考虑的重点。此外,5G时代将产生大量的行业应用,运营商会将网络能力进一步开放,这样就会导致用户个人信息、用户使用的业务信息等暴露在比较开放的网络节点里。如果没有增强的隐私保护技术,那么就很有可能有恶意攻击者借助大数据分析等技术获得用户隐私,对用户的信息安全造成威胁。杨红梅认为,综合各种因素考虑,5G网络需要具备几大安全能力:一、形成统一的认证架构;二、多层次的切片安全;三、按需的安全保护;四、多样的安全认证管理体系;五、网络安全能力开放;六、灵活的隐私保护机制。运营商如何推进5G网络架构重构?“不同的运营商需要根据自身网络的现状制定相应的演进策略。”在杨红梅看来,部署一个新的网络时,如何实现新网络和现有网络的融合,如何使现有网络发挥最大的作用,从而保护运营商的已有投资,同时又能满足新的业务需求是重点问题。因此面向5G可能会出现多种不同的过渡型网络部署方案。值得一提的是,5G时代运营商还要加快推动优化运营。随着一些垂直行业的新业务的落地,运营商无论是在商业模式还是运营模式上都需要进行一些创新和调整,以适应新的需求。杨红梅建议,运营商面向5G的优化运营可以从精细化管理、差异化服务、能力开放等几个方面展开。SDN/NFV,奠定5G网络基石面向即将到来5G时代,电信运营商正在加大网络重构的力度,而SDN/NFV技术的规模部署,将为5G网络架构重构奠定坚实的基石。“5G时代的应用将成为NFV的关键网络应用。”中国移动蔡慧认为,当前的NFV产业已经初具雏形,这无疑将为未来5G应用落地提供有力支撑。未来,5G时代的服务化架构设计,网络切片、边缘计算等功能和特性的实现,都需要建立在NFV孵化成熟以及NFV能够成功部署的基础上,因此,5G对于NFV是有很高的期待的,为了迎接5G时代的带来,业界需要推进NFV的快速部署。“中国电信的网络重构考虑了5G时代的需求。”中国电信北京研究院史凡表示,面向5G时代中国电信将会推进基于SDN/NFV的网络重构,今年将在SDN和NFV上展开一系列的工作,未来三年的目标是将有一半政企客户组网业务能够基于SDN技术手段来实现。同时,2020年中国电信的网络基础设施中将有40%实现虚拟化。事实上,除了电信运营商,厂商们也正在推进SDN/NFV的落地。“5G时代,网络云化的趋势将愈演愈烈,这意味着网络不仅要高效,还要实现虚拟化,同时具备弹性。”英特尔严峰认为,电信网络5个9甚至6个9的高可靠性和高转发性能要求,以及数据面的分布式部署,对整个电信网络云化提出了更高的要求。如何将IT 和云计算的灵活性和弹性部署应用到电信云里,是整个行业面临的一个挑战。因而英特尔目前正在做的工作,就是携手合作伙伴,凝聚产业链的合力,将这些代表不同方向的需求“靠在一起”。严峰透露,英特尔倡导并实践开源,因此在推进NFV发展上,英特尔正在借助开源平台的力量,将一些关键的技术集成在一起。同时,再将推进过程中暴露出来的技术问题反馈到开源社区中去,从而更高效有力地推进包括芯片、网卡、加速器、软件等各方面的技术创新步伐,最终助力NFV技术的成熟和规模部署,迎接5G时代的全面到来。

2977
自MySQL 5.6开始,在索引方面有了一些改进,比如索引条件下推(Index condition pushdown,ICP),严格来说属于优化器层面的改进。如果简单来理解,就是优化器会尽可能的把index condition的处理从Server层下推到存储引擎层。举一个例子,有一个表中含有组合索引idx_cols包含(c1,c2,…,cn)n个列,如果在c1上存在范围扫描的where条件,那么剩余的c2,…,cn这n-1个上索引都无法用来提取和过滤数据,而ICP就是把这个事情优化一下。我们在MySQL 5.6的环境中来简单测试一下。我们创建表emp,含有一个主键,一个组合索引来说明一下。create table emp( empno smallint(5) unsigned not null auto_increment, ename varchar(30) not null, deptno smallint(5) unsigned not null, job varchar(30) not null, primary key(empno), key idx_emp_info(deptno,ename) )engine=InnoDB charset=utf8; 当然我也随机插入了几条数据,意思一下。insert into emp values(1,'zhangsan',1,'CEO'),(2,'lisi',2,'CFO'),(3,'wangwu',3,'CTO'),(4,'jeanron100',3,'Enginer'); ICP的控制在数据库参数中有一个优化器参数optimizer_switch来统一管理,我想这也是MySQL优化器离我们最贴近的时候了。可以使用如下的方式来查看。show variables like 'optimizer_switch'; 当然在5.6以前的版本中,你是看不到index condition pushdown这样的字样的。在5.6版本中查看到的结果如下:# mysqladmin var|grep optimizer_switch optimizer_switch | index_merge=on,index_merge_union=on,index_merge_sort_union=on,index_merge_intersection=on,engine_condition_pushdown=on,index_condition_pushdown=on,mrr=on,mrr_cost_based=on,block_nested_loop=on,batched_key_access=off,materialization=on,semijoin=on,loosescan=on,firstmatch=on,subquery_materialization_cost_based=on,use_index_extensions=on下面我们就用两个语句来对比说明一下,就通过执行计划来对比。set optimizer_switch = "index_condition_pushdown=off" > explain select * from emp where deptno between 1 and 100 and ename ='jeanron100'; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | emp | ALL | idx_emp_info | NULL | NULL | NULL | 4 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 而如果开启,看看ICP是否启用。set optimizer_switch = "index_condition_pushdown=on";> explain select * from emp where deptno between 10 and 3000 and ename ='jeanron100'; +----+-------------+-------+-------+---------------+--------------+---------+------+------+-----------------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+-------+---------------+--------------+---------+------+------+-----------------------+ | 1 | SIMPLE | emp | range | idx_emp_info | idx_emp_info | 94 | NULL | 1 | Using index condition | +----+-------------+-------+-------+---------------+--------------+---------+------+------+-----------------------+ 1 row in set (0.00 sec)如果你观察仔细,会发现两次的语句还是不同的,那就是范围扫描的范围不同,如果还是用原来的语句,结果还是有一定的限制的。> explain select * from emp where deptno between 1 and 300 and ename ='jeanron100'; +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ | 1 | SIMPLE | emp | ALL | idx_emp_info | NULL | NULL | NULL | 4 | Using where | +----+-------------+-------+------+---------------+------+---------+------+------+-------------+ 1 row in set (0.00 sec)这个地方就值得好好推敲了。

2535
14248

