



2562
2787
3568

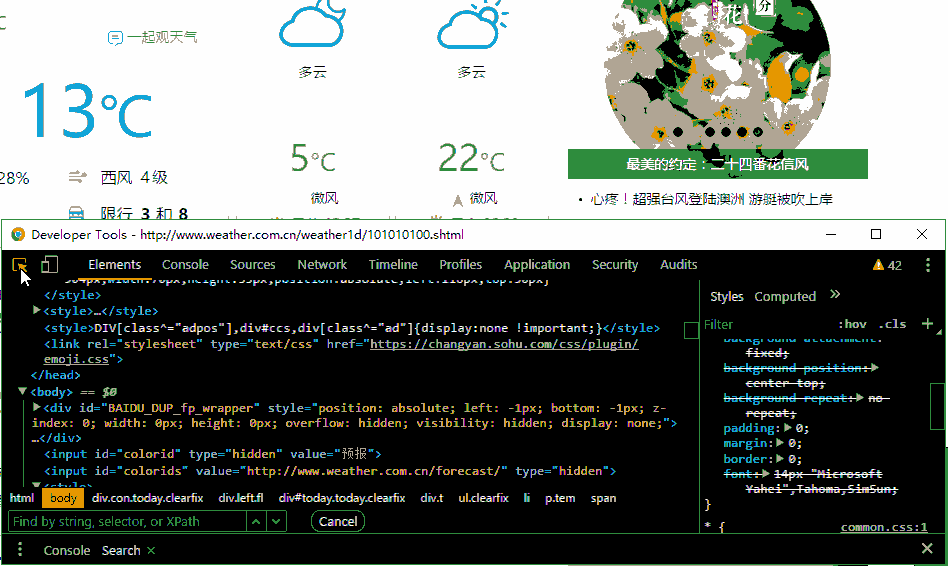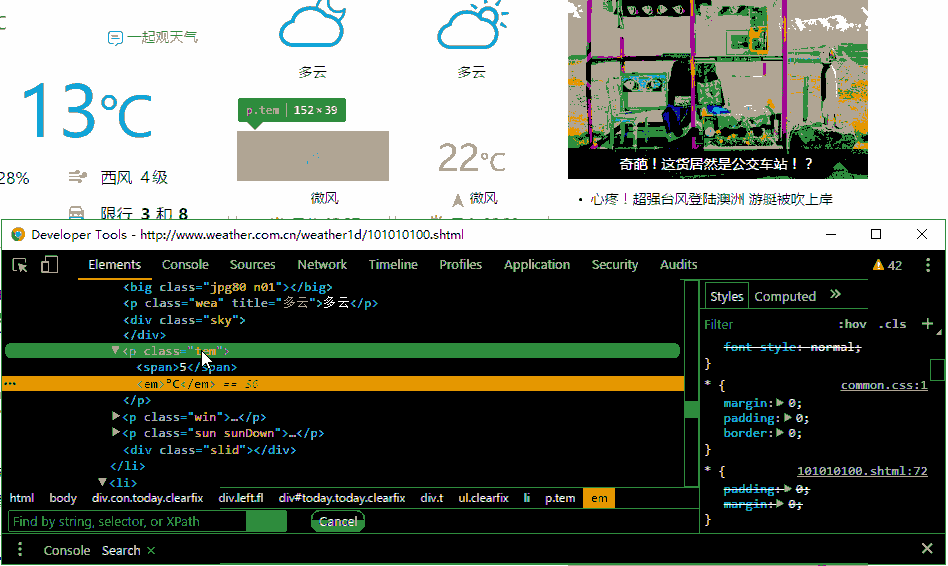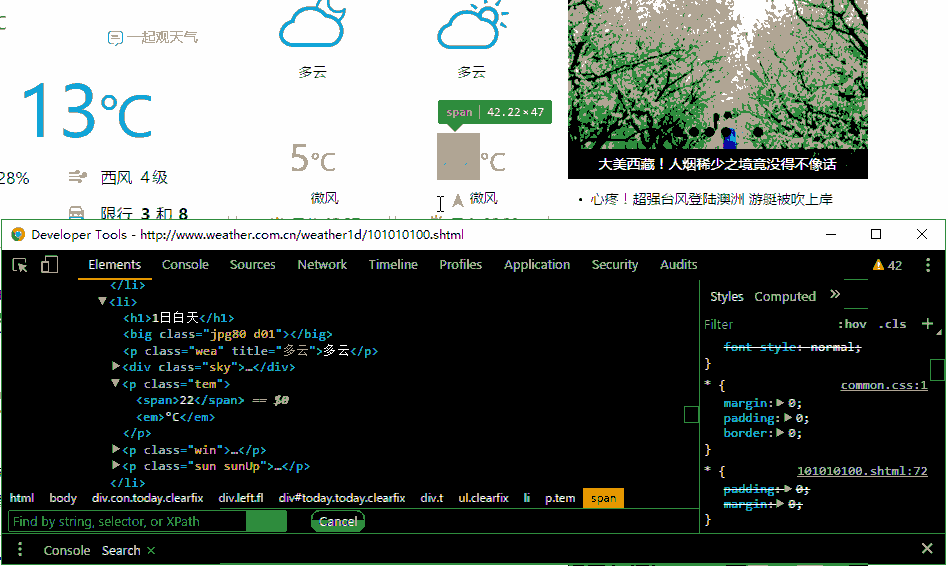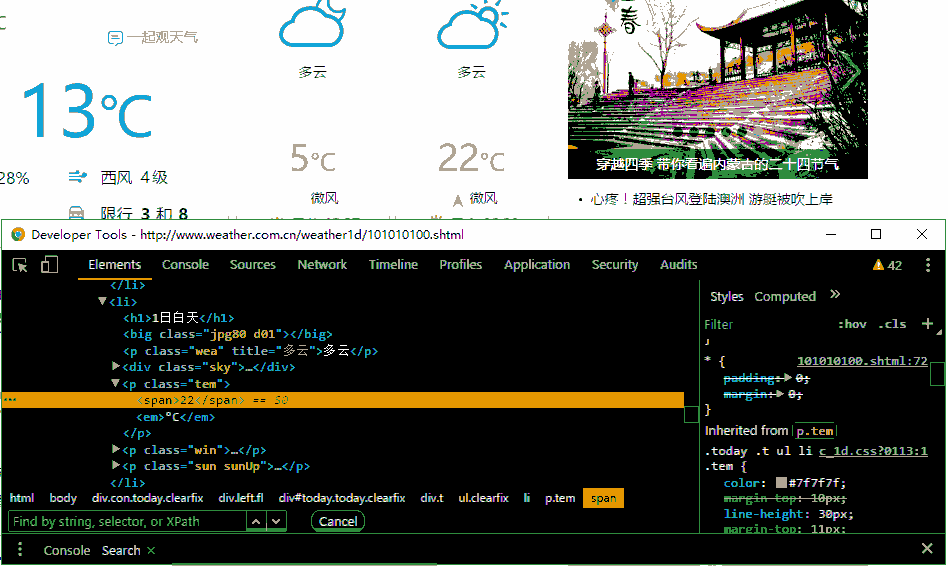
刚开始看爬虫文章的时候,走了不少弯路,我希望我的文章能给你带来一些启发本文涉及到的技能查看网页源代码和检查元素requests使用BeautifulSoup使用这三招就是爬取简单网站的全部招数,跟着思路往下看查看网页源代码和检查元素不要觉得很简单,这两招是爬虫的基础。如果你熟悉这两招,简单网站的爬虫,你就学会了一半。一般来说,检查元素中看到的内容都会在网页源代码中出现。今天我选取的这个例子,情况特殊,检查元素中看到的内容部分会在网页源代码中出现爬北京的白天和夜间温度北京天气的网址:http://www.weather.com.cn/weather1d/101010100.shtml下面是源代码,我会有注释的,跟着一起读一读Talk is cheap. Show you the code# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests # 导入requests模块
from bs4 import BeautifulSoup # 从bs4包中导入BeautifulSoup模块
# 设置请求头
# 更换一下爬虫的User-Agent,这是最常规的爬虫设置
headers = {"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/57.0.2987.110 Safari/537.36'}
# 需要爬取的网址
url ="http://www.weather.com.cn/weather1d/101010100.shtml"
# 发送请求,获取的一个Response对象
web_data = requests.get(url,headers=headers)
# 设置web_data.text会采用web_data.encoding指定的编码,一般情况下不需要设置,requests会自动推断
# 鉴于网页大部分都是采取utf-8编码的,所以设置一下,省去一些麻烦
web_data.encoding = 'utf-8'
# 得到网页源代码
content = web_data.text
# 使用lxml解析器来创建Soup对象
soup = BeautifulSoup(content, 'lxml')
# 为什么要创建一个Soup对象,还记得浏览器中的检查元素功能嘛
# Soup对象可以方便和浏览器中检查元素看到的内容建立联系,下面会有动画演示
# 使用css selector语法,获取白天和夜间温度,下面有动画演示
tag_list = soup.select('p.tem span')
# tag_list[0]是一个bs4.element.Tag对象
# tag_list[0].text获得这个标签里的文本
day_temp = tag_list[0].text
night_temp = tag_list[1].text
print('白天温度为{0}℃\n晚上温度为{1}℃'.format(day_temp, night_temp))css seletor语法值得提出的是当搜索'p.temem'时,刚好有2个匹配的对象,分别对应白天温度和夜间温度,这一点非常重要,如果匹配个数大于或者小于2,那么说明你的css selector写错了爬多个城市的白天和夜间温度搜索不同的城市天气,观察网址的变化。观察网址的变化是爬虫中最主要的本领之一# -*- coding: utf-8 -*-
__author__ = 'duohappy'
import requests
from bs4 import BeautifulSoup
headers = {"User-Agent":'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/57.0.2987.110 Safari/537.36'}
# 建立城市和网址特殊部分的对应关系
weather_code = {'北京':'101010100','上海':'101020100','深圳':'101280601', '广州':'101280101', '杭州':'101210101'}
city = input('请输入城市名:') # 仅仅能输入北京,上海,广州,深圳,杭州
url ="http://www.weather.com.cn/weather1d/{}.shtml".format(weather_code[city])
web_data = requests.get(url,headers=headers)
web_data.encoding = 'utf-8'
content = web_data.text
soup = BeautifulSoup(content, 'lxml')
tag_list = soup.select('p.tem span')
day_temp = tag_list[0].text
night_temp = tag_list[1].text
print('白天温度为{0}℃\n晚上温度为{1}℃'.format(day_temp, night_temp))

3
0 2475天前
2918
【百度快照】禁止百度保留快照的代码:noarchive很多站点出于隐私的考虑不希望百度保留快照,网上也在讨论如何禁止百度保留快照的方法。其实百度早已对此有过说明,但藏在一篇不起眼的文章中不引人注目,导致依然非常多的人不清楚该如何操作。要防止所有搜索引擎显示您网站的快照,请将此元标记置入网页的部分:<meta name="robots" content="noarchive">要允许其他搜索引擎显示快照,但仅防止百度显示,请使用以下标记:<meta name="Baiduspider" content="noarchive">注:此标记只是禁止百度显示该网页的快照,并不会影响网页建入索引,同时垃圾网页也不可能依靠此手段逃避百度的判罚。
3
0 2475天前
2888
1、我们首先进QQ空间进入“相册“点击进去后,我们点右上角的“回收站”。2、如果空间还没有设置密码的朋友,点击“日志”,弹出的页面提示你开启回收站功能,开启回收站后,你删除的邮件,QQ空间将为你保存三个月。或者直接输入你的QQ空间密码。我们点“启动回收站”,弹出对话框要我们设置密码。我们输俩遍后,点确定。但是这密码不能和QQ密码相同。3、设置好后,我们看到我最近三个月删除的照片。如果我们要还原的话,可以勾选照片,进行还原。黄钻用户的话,可以恢复一年之内删除的照片。但前提是你一直续费和开启回收站功能。4、我们勾选一张照片,再点击“还原”。弹出对话框,我们选择恢复到哪个相册,点确定后,再提示你输入密码。再选择点确定。提示我们恢复成功,我们可以在我们之前选择的目录里找到我们刚才恢复的照片了。



9
0 2481天前

